


텍스트 처리 소개: Python으로 빠른 사전 만들기(1부)

목차
[1부]
[2부]
[3부]
[4부]
텍스트 처리의 중요성
제 이름은 다카덴샤 개발국의 가와카미입니다.
현재 신경망을 사용한 자연어 처리가 번창하고 있습니다.
Takadensha는 또한 기존의 규칙 기반 번역(RBMT) 및 통계적 번역(SMT)에서 발전된 기술을 활용합니다.
우리는 신경망의 응용 작업인 신경 번역(NMT)을 연구하고 있습니다.
자연어 처리의 세계에서 워프 스레드 역할을 하는 중요한 기술은 텍스트 처리입니다.
이번에는 텍스트 처리에 대한 소개로, Python을 어느 정도 알고 있는 사람들을 위해 dictionary program
만드는 방법을 소개합니다. 우리는 구현을 가능한 한 간단하고 실용적으로 만드는 것을 목표로 합니다.
이 문서의 예제 프로그램은 jupyter-notebook에서 Python 3.6.x를 사용합니다.
사전 조회란 무엇입니까(이 문서에서 다루는 내용)
사전 조회 프로그램의 목적은 텍스트 데이터(예: 위키피디아 기사)를
원하는 문자열(표제어; 예를 들어, Wikipedia는 제목 문자열에 대한 검색입니다).
단순화를 위해 표제어에 대한 정확한 일치 검색을 고려해 보겠습니다.
텍스트 데이터를 검색하고 사전에 등록된 표제어의 문자열을 치는 경우
사전에 등록된 단어의 의미를 표시합니다. 이 의미에 대한 자세한 내용은 다음을 참조하십시오.
데이터베이스(특히 키-값 저장소와 같은 비관계형 데이터베이스)
그것을 저장하는 것은 생각할 수 있습니다. 이건 다음에 미뤄두겠지만 이번에는
"검색"의 전반부에만 초점을 맞추고 검색 인덱싱이 작동하는 방식을 살펴보겠습니다.
참고: 일반적인 아이디어를 이미 알고 있고 프로그래밍에 대해 읽고 싶다면
다음 이야기는 건너 뛰고 "이중 배열 (1)의 Python 구현"부터 시작하십시오.
Trie Tree(TRIE)의 기본 개념
문자열 일치를 검색할 때 가장 먼저 떠오르는 것은 연관 배열입니다.
파이썬 표준 딕셔너리도 마찬가지입니다. 올해의 테마에 대해 하나 더 기억하고 싶은 것이 있습니다
Trie는 나무(trie)입니다. 파이썬의 표준 라이브러리에는 포함되어 있지 않으니 만들어 봅시다.
이제 아래 그림에서 Trie 트리의 예를 살펴보겠습니다. "*"는 단어 끝에 있는 랜드마크입니다.
얼마나 많은 단어가 저장되어 있는지 세어 봅시다.
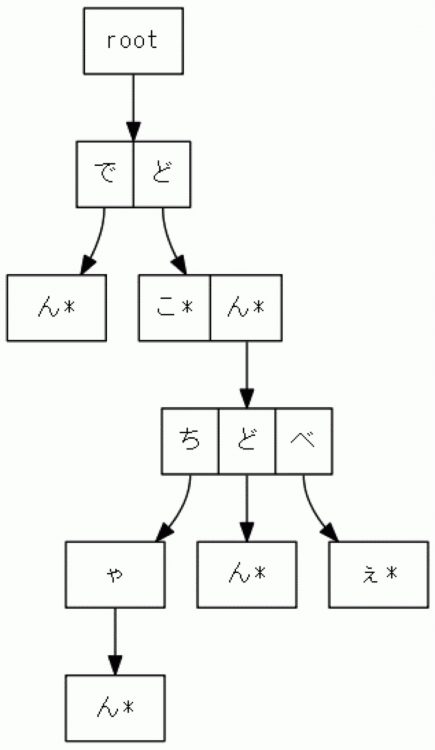
루트에서 "*"로 이동해 보겠습니다.
'굴', '어디', '돈', '돈짱', '돈돈', '돈베', '돈베'의 6가지 단어가 있습니다.
"↓"의 끝은 다음 문자를 나타내는 자식의 노드 (node)이며, 서로 옆에 붙어있는 사각형은 다음과 같습니다.
형제 노드에서 같은 위치에 있는 문자 선택을 나타냅니다.
엄밀히 말하면 "하나의 노드가 문자 데이터에 의해 다음 노드로 전환된다"고 생각하기 때문에,
문자 데이터는 화살표에 기록됩니다. (자세한 내용은 학술 서적을 참조하시기 바랍니다.)
더 쉽게 구현할 수 있도록 이진 트리로 만들어 보겠습니다.
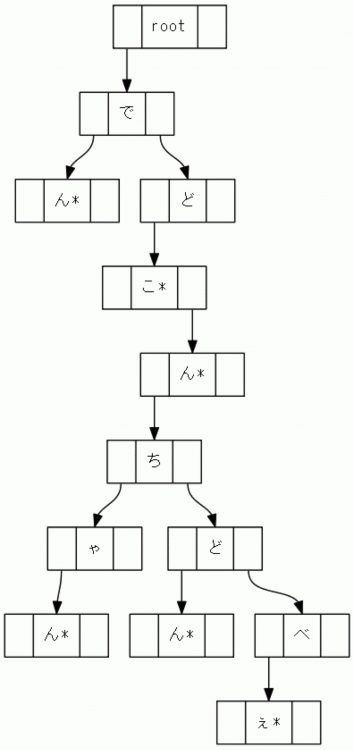
첫 번째 그림보다 인간에게 더 혼란 스럽지만 기본은 동일합니다. 이 그림의 Trie 트리에서
왼쪽의 "↓" 끝은 자식의 노드이고 오른쪽의 "↓" 끝은 형제 노드입니다.
"*"로 표시된 노드를 리프 노드라고 합니다.
이런 식으로 루트에서 리프 노드까지 문자를 차례로 검색하여 사전을 조회할 수 있습니다.
구현을 고려해 보겠습니다. 먼저 노드에 대한 클래스를 만듭니다. 회원으로서:
왼쪽 노드의 인덱스 번호입니다
오른쪽 노드의 인덱스 번호
- 노드의 문자 데이터(또는 해당 문자 코드)
리프 노드의 경우, 단어의 의미로 기록되는 데이터의 번호 (예 : 리프 노드가 아닌 경우 -1)
그보다 더 많으면 좋을 것입니다. 다음으로 Trie 나무 클래스를 만듭니다.
먼저 노드(위 그림의 13)를 배열로 사용하겠습니다.
남은 것은 Trie 트리(?)에서 노드를 등록하고 검색하는 방법을 작성하는 것입니다. )
이러한 간단한 설계 및 구현으로도 고속 검색이 가능하며 자연어 처리의 다양한 작업에 사용할 수 있습니다.
충분히 유용합니다. 엄청난 양의 텍스트 데이터를 처리할 때 Python이나 C++11을 사용하는 경우가 많습니다.
나는 그런 Trie tree 프로그램을 작성하고 활용하곤 했다.
Double Array 정보
자, 여기 문제가 있습니다. 트리 트리는 다양한 디자인과 구현으로 제공됩니다.
현재 주류 알고리즘을 이중 배열이라고 합니다.
제안된 것은 20년 이상의 역사를 가지고 있습니다만, 이해의 문턱은 조금 높았습니다.
최근까지만 해도 '전문가들이 좋아하는 도구'로 취급되고 있었다고 생각합니다.
이제, 씹어먹는 매우 알기 쉬운 설명을 읽을 수 있기 때문에, 일반인에게 사용할 수 있습니다 (간단히 말하면,
저처럼 정상적인 이해를 가진 사람도 접근할 수 있는 기술입니다.
"정보과학 석사학위로 이해할 수 있는 이중배열"
http://d.hatena.ne.jp/takeda25/20120219/1329634865
웹에서도 읽을 수 있는 알기 쉬운 설명 기사에서 이것은 선구자입니다.
"형태 학적 분석의 이론과 구현"
https://www.amazon.co.jp/dp/4764905779
형태 분석의 바이블. 4장에는 몇 페이지가 있지만 훌륭한 설명이 있습니다.








