


자연어 처리/텍스트 처리

많은 수의 이중 언어 말뭉치의 고속 검색을 위한 도구
텍스트 데이터의 노이즈를 제거하고 유사한 문장 및 번역을 검색하는 데 유용합니다.
대상 이중 언어 말뭉치의 필드에 관계없이 사용할 수 있습니다.
대상 이중 언어 말뭉치의 필드에 관계없이 사용할 수 있습니다.
쓰다
이 기술은 많은 양의 텍스트 데이터에서 유사한 문장 예제를 추출하는 데 사용할 수 있습니다.
또한 전문 용어 사전을 구축하기 위한 도구를 제공합니다.
또한 전문 용어 사전을 구축하기 위한 도구를 제공합니다.
처리 화면의 예

플로우 예 1
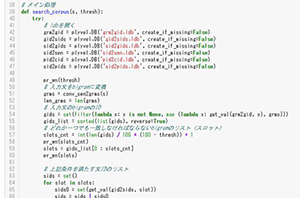
플로우 예 2
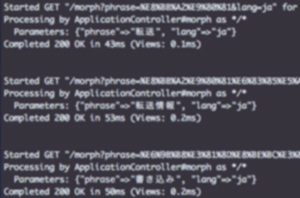
플로우 예 3
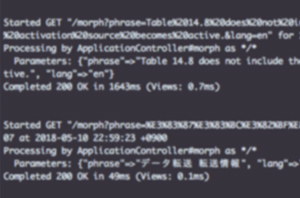
플로우 예 4
입력 텍스트 및 샘플 검색 결과
- 입력 문장
- 비행기로 상하이에 갈 것입니다.
- 검색 결과
- 그는 비행기를 타고 상하이에 가기로 결정했다. 他决定坐飞机去上海.
- 다음 달 초에 상하이에 갈 예정입니다. 下月初我要到上海去.
- 비행기는 많이 타지만 서툴러요. 我经常坐飞机,但我不喜欢飞机.
임상시험 수락 양식
아래 양식을 작성하여 무엇을 시도하고 싶은지 알려주십시오.
당사에서 녹화 한 조작 화면을 동영상으로 확인할 수 있습니다.
기술자의 메시지
일반적인 정확한 일치 및 부분 일치 검색 외에도 유사한 문장을 검색하기 위한 특수 알고리즘을 만들었습니다.
또한 수십만 개의 문장에서 이러한 검색 속도를 높일 수 있는 방법을 고안하고 있습니다.
이 메커니즘은 사전 예제, 검색, 번역 메모리 등과 같은 다양한 것들에 적용될 수 있다고 생각합니다.
Linux에서 실행되며 브라우저에서 액세스할 수 있습니다.
또한 수십만 개의 문장에서 이러한 검색 속도를 높일 수 있는 방법을 고안하고 있습니다.
이 메커니즘은 사전 예제, 검색, 번역 메모리 등과 같은 다양한 것들에 적용될 수 있다고 생각합니다.
Linux에서 실행되며 브라우저에서 액세스할 수 있습니다.



